“Thanks to Blingee I discovered who I am”
“2021.2.4 This can be my last blingee… Is too much hard making blingess since I can’t find too much stamps… I wanna thank you all for comments, votes, friendship, I love ya guys.. and thank you Blingee Team for making this site. This site gave me a lot fun. I’m sad it’s end… However still there inside of me, part of me feels that there is a some hope. Anyway thanks for these years here. I’m here almost 9 years, in next month will 9 year in 1st March. I never forget you all ♥ Thanks ♥ PS. on P****x also I am Klaudia1998, I hope you’ll found ;3”


OL: Klaudia (sorry if I assumed wrongly and it is not your real name!), I was very happy you reacted to my tweet about the Blingee community mourning the service and at the same time supporting each other in the hope that it is not the end!Thank you for agreeing to talk to me, and adding me to your circle.
I understood from your forum entries that Blingee.com was (or still is) a big part of your life. And that’s what I want to talk about with you. But let me start with something that puzzles right now. How come a few new blingees appeared in your profile 2 days ago? How did you make them if Flash is still dead, and there is no non-flash editor on the website?!
K: I’m also glad I can tell you about my experience and I’m sorry for my not perfect English. Well, on Blingee there are maybe 100 people who are still making. Last year after Flash was discontinued, one of them told me about an old version of flash which I downloaded on my old laptop as well as the Pale Moon browser and tried it on February 2, 2021, but then deleted the programmes because I heard about the risks. Now I installed it again and I’m making new blingees again, because I missed it so much. I’m not sure it’s 100% safe but there was only one person who got hacked.
OL: What exactly do you mean by “got hacked”?
K: She said she lost her accounts. Later she wrote on Blingee that she got hacked and people were afraid they would lose their accounts too but I didn’t hear anyone else got hacked.
OL: How did you come up with the number of 100 blingee users still being active? And, how many people do you think were still active before the editor stopped working?
K: When I joined Blingee there were a lot of people, but then less and less. People stopped making or deleted their accounts. In the end of 2020 right before Flash was over, people started to make a lot again, me too, because we thought it’s the end. I don’t know how many people are still there, maybe not 100, but very few.
OL: Is 1998 the year of your birth? If I assume correctly after reading the goodbye comment under your “last” blingee, you came to the service in 2012 when you were 14, right? Can you tell me what you remember about that?
K: Yes, 1998 is the year of my birth. I came to this service when I was 13 years old. I discovered the website in February and uploaded photos of my hamster to test the effects and thought it was very cool. So on March 1 I made an account there.
OL: So, 10 years! How many blingees and samps have you made in these years?
K: Over 1800 blingees, and a lot of stamps, more than 6000 I think.
OL: Which is your favorite one? Or some that you are really proud of?
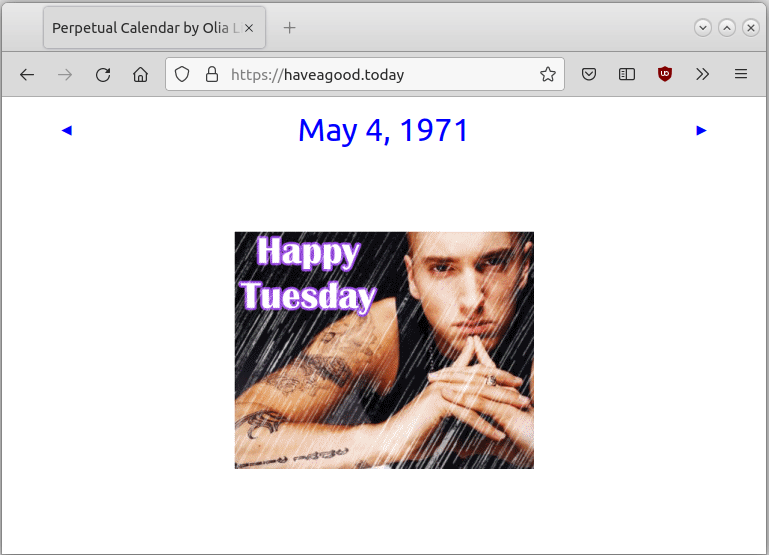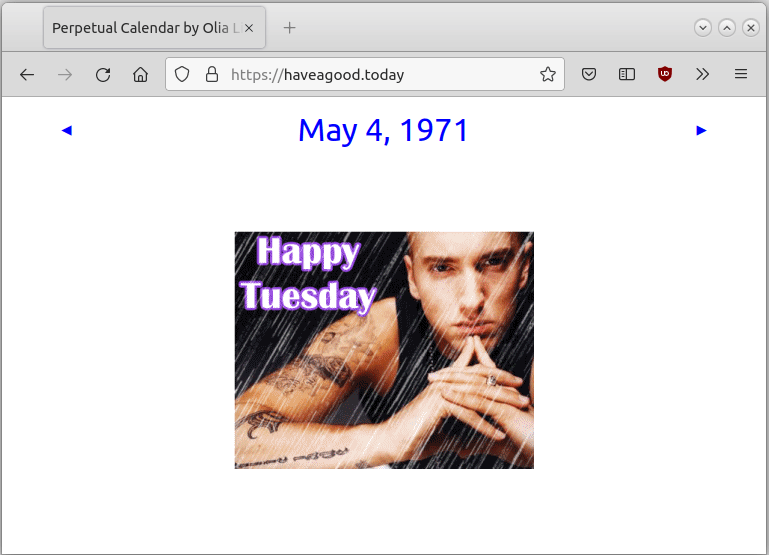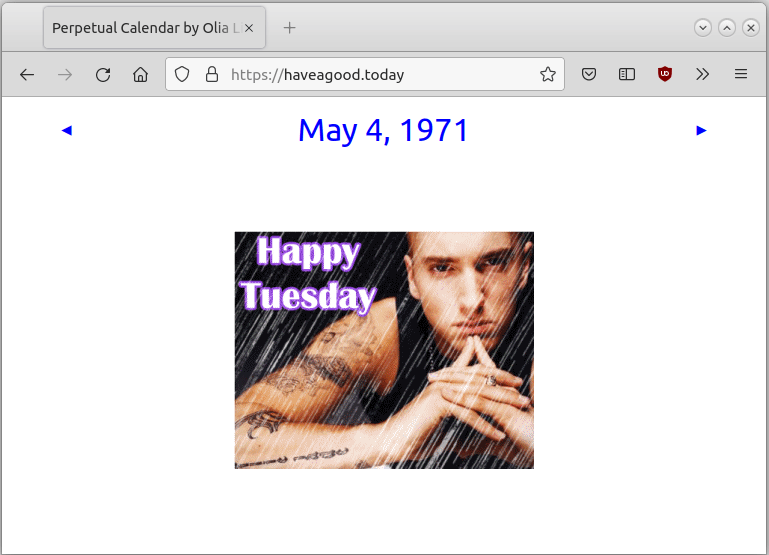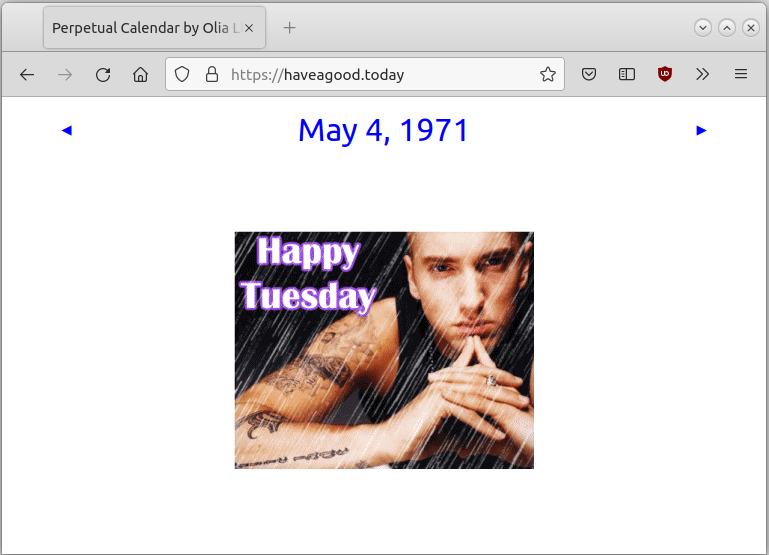
K: Usually I cut out stamps when I need something for my own blingee but can’t find it on the platform. It takes time to make them, but it is worth it. To be honest I can’t decide which is my favorite, I’m proud of almost all of them, but there’s one which I really like, though it was used only one time and this I used it for one of my favorite blingee, in 2012.


… continue reading →











 at the bottom of
at the bottom of 





{kind=link}
{kind=link}
{kind=link}
{kind=link}